【Python】Streamlitを使ってデータを簡単に可視化してみる

1.概要
Streamlit は、Pythonで書かれたスクリプトをそのままインタラクティブなWebアプリとして表示できるオープンソースフレームワークです。
「データ分析をWebアプリ化したいけれど、HTMLやJavaScriptを書くのは面倒」というデータサイエンティストやエンジニアに最適です。
- 開発元:Streamlit Inc.(現在は Snowflake 社に買収済み)
- 対象:データ分析・機械学習・可視化・社内ツールなど
2.特徴
| 項目 | 説明 |
|---|---|
| 簡単な記述 | 普通のPythonスクリプトにst.write()などを追加するだけでアプリ化可能。 |
| 即時反映 | コードを変更するとブラウザが自動で更新される(ホットリロード機能)。 |
| 豊富なウィジェット | スライダー・セレクトボックス・ファイルアップロードなどのUI要素が標準装備。 |
| データ可視化連携 | matplotlib、plotly、pandasなどのグラフをそのまま表示可能。 |
| 軽量なサーバー内蔵 | FlaskやFastAPIなどの設定不要で、ローカルサーバーが自動で起動。 |
| デプロイ容易 | streamlit cloud や Docker、または任意のクラウド(OCI, AWS, GCPなど)で公開可能。 |
3.利点(使うメリット)
- 開発スピードが速い
数行のコードで動くデータアプリが作れるため、プロトタイピングに最適です。 - Pythonだけで完結
HTML/CSS/JavaScriptを知らなくてもWebアプリが作れる。 - データサイエンス向けに最適化
NumPy・Pandas・Matplotlibなどと自然に統合でき、データフレームをきれいに表示できます。 - 社内共有に便利
チームで分析結果やモデルを共有するダッシュボードをすぐに構築可能。 - 拡張性
st.session_stateによる状態管理、st.experimental_*系のAPIで高度な挙動も実現可能。
4.注意点・制約
- 大規模アプリには不向き
ページ遷移や複雑なルーティング機能が標準ではないため、業務システム規模の開発には不向き。 - 非同期処理が制限される
一部の非同期処理(async/await)は制限があり、リクエスト中はUIがブロックされやすい。 - ステート管理の癖
Streamlitは「毎回スクリプトを再実行」する設計のため、変数の保持にはst.session_stateが必要。 - デザインの自由度が低い
レイアウトやスタイルのカスタマイズは限定的。美しいUIを作りたい場合はCSSの工夫が必要。 - 認証・セキュリティ機能が限定的
ログイン機構などは標準で用意されていないため、外部ライブラリやリバースプロキシで補う必要があります。
5.代表的なユースケース
- データ分析結果のダッシュボード
- 機械学習モデルの推論デモ(例:画像分類やテキスト生成)
- 社内レポート可視化ツール
- ファイルアップロード+自動処理ツール
- AI/LLMとのインタラクティブチャットUI
6.利用方法
-
パッケージをインストール
pip install streamlit -
アプリを起動
$ streamlit run app.py -
起動時に表示されるURLにアクセス
You can now view your Streamlit app in your browser.
Local URL: http://localhost:8501
Network URL: http://192.168.1.5:8501
ここでは、投資信託の月次データの可視化をしてみます。
ブラウザ表示後に、ブラウザ上で例と同様のフォーマットのデータを貼り付けるとリアルタイムでグラフが再描画されるようにします。
# app.py
# -*- coding: utf-8 -*-
import io
import re
import pandas as pd
import streamlit as st
import plotly.graph_objects as go
st.set_page_config(page_title="S&P 500 可視化", layout="wide")
st.title("S&P 500 月次データの可視化(Streamlit)")
st.caption("タブ区切り(TSV)のまま貼り付けOK。日本語日付(2025年10月01日)にも対応。")
DEFAULT_DATA = """日付\t終値\t始値\t高値\t安値\t出来高\t変化率 %
2025年10月01日\t6791.73\t6653.86\t6807.06\t6546.53\t\t+1.54%
2025年9月01日\t6688.46\t6401.51\t6699.52\t6360.58\t\t+3.53%
2025年8月01日\t6460.26\t6287.28\t6508.23\t6212.69\t\t+1.91%
2025年7月01日\t6339.39\t6187.25\t6427.02\t6177.97\t\t+2.17%
2025年6月01日\t6204.95\t5896.68\t6215.08\t5861.43\t\t+4.96%
2025年5月01日\t5911.69\t5625.14\t5968.61\t5578.64\t\t+6.15%
2025年4月01日\t5569.06\t5597.53\t5695.31\t4835.04\t\t-0.76%
2025年3月01日\t5611.85\t5968.33\t5986.09\t5488.73\t\t-5.75%
2025年2月01日\t5954.5\t5969.65\t6147.43\t5837.66\t\t-1.42%
2025年1月01日\t6040.53\t5903.26\t6128.18\t5773.31\t\t+2.70%
2024年12月01日\t5881.63\t6040.11\t6099.97\t5832.3\t\t-2.50%
2024年11月01日\t6032.38\t5723.22\t6044.17\t5696.51\t\t+5.73%
2024年10月01日\t5705.45\t5757.73\t5878.46\t5674\t\t-0.99%
2024年9月01日\t5762.48\t5623.89\t5767.37\t5402.62\t\t+2.02%
2024年8月01日\t5648.4\t5537.84\t5651.62\t5119.26\t\t+2.28%
2024年7月01日\t5522.3\t5471.08\t5669.67\t5390.95\t\t+1.13%
2024年6月01日\t5460.48\t5297.15\t5523.64\t5234.32\t\t+3.47%
2024年5月01日\t5277.51\t5029.03\t5341.88\t5011.05\t\t+4.80%
2024年4月01日\t5035.69\t5257.97\t5263.95\t4953.56\t\t-4.16%
2024年3月01日\t5254.35\t5098.51\t5264.85\t5056.82\t\t+3.10%
2024年2月01日\t5096.27\t4861.11\t5111.06\t4853.52\t\t+5.17%
2024年1月01日\t4845.65\t4745.2\t4931.09\t4682.11\t\t+1.59%
2023年12月01日\t4769.83\t4559.43\t4793.3\t4546.5\t\t+4.42%
2023年11月01日\t4567.8\t4201.27\t4587.64\t4197.74\t\t+8.92%
"""
with st.expander("データを編集(タブ区切りTSV形式)", expanded=False):
raw = st.text_area("ここに貼り付け/編集してください", DEFAULT_DATA, height=260, key="raw_tsv")
def parse_jp_date(s: str) -> str:
# "2025年10月01日" -> "2025-10-01"
s = s.strip()
s = s.replace("年", "-").replace("月", "-").replace("日", "")
return s
@st.cache_data
def load_df(text: str) -> pd.DataFrame:
df = pd.read_csv(io.StringIO(text), sep="\t")
# 日付変換
df["日付"] = pd.to_datetime(df["日付"].apply(parse_jp_date), format="%Y-%m-%d", errors="coerce")
# 数値列のクレンジング
for col in ["終値", "始値", "高値", "安値", "出来高"]:
if col in df.columns:
df[col] = pd.to_numeric(df[col].astype(str).str.replace(",", ""), errors="coerce")
# 変化率 % -> 数値(%)
if "変化率 %" in df.columns:
df["変化率(%)"] = (
df["変化率 %"]
.astype(str)
.str.replace("%", "", regex=False)
.str.replace("+", "", regex=False)
.str.replace(",", "", regex=False)
)
# マイナス符号はそのまま、空欄はNaN
df["変化率(%)"] = pd.to_numeric(df["変化率(%)"], errors="coerce")
# 昇順にソート(古い→新しい)
df = df.sort_values("日付").reset_index(drop=True)
# リターン再計算(保険)
if "終値" in df.columns:
df["月次リターン(%)"] = df["終値"].pct_change() * 100
df["累積リターン(%)"] = (1 + df["終値"].pct_change().fillna(0)).cumprod().sub(1) * 100
return df
df = load_df(raw)
# 概要メトリクス
col1, col2, col3, col4 = st.columns(4)
if len(df) >= 2:
latest = df.iloc[-1]
prev = df.iloc[-2]
col1.metric("最新 終値", f"{latest['終値']:.2f}", f"{latest['終値']-prev['終値']:+.2f}")
col2.metric("最新 月次リターン", f"{latest['月次リターン(%)']:.2f}%")
col3.metric("累積リターン(全期間)", f"{df['累積リターン(%)'].iloc[-1]:.2f}%")
col4.metric("期間", f"{df['日付'].min().date()} → {df['日付'].max().date()}")
st.markdown("### 終値(ライン)")
st.line_chart(df.set_index("日付")[["終値"]])
st.markdown("### ローソク足(始値・高値・安値・終値)")
fig = go.Figure(
data=[
go.Candlestick(
x=df["日付"],
open=df["始値"],
high=df["高値"],
low=df["安値"],
close=df["終値"],
showlegend=False,
)
]
)
fig.update_layout(height=500, margin=dict(l=0, r=0, t=10, b=0))
st.plotly_chart(fig, use_container_width=True)
left, right = st.columns(2)
with left:
st.markdown("### 月次リターン(%)")
st.bar_chart(df.set_index("日付")[["月次リターン(%)"]])
with right:
st.markdown("### 累積リターン(%)")
st.line_chart(df.set_index("日付")[["累積リターン(%)"]])
st.markdown("### データ(クレンジング後)")
st.dataframe(
df[["日付", "終値", "始値", "高値", "安値", "出来高", "変化率(%)", "月次リターン(%)", "累積リターン(%)"]],
use_container_width=True,
hide_index=True,
)
実行結果
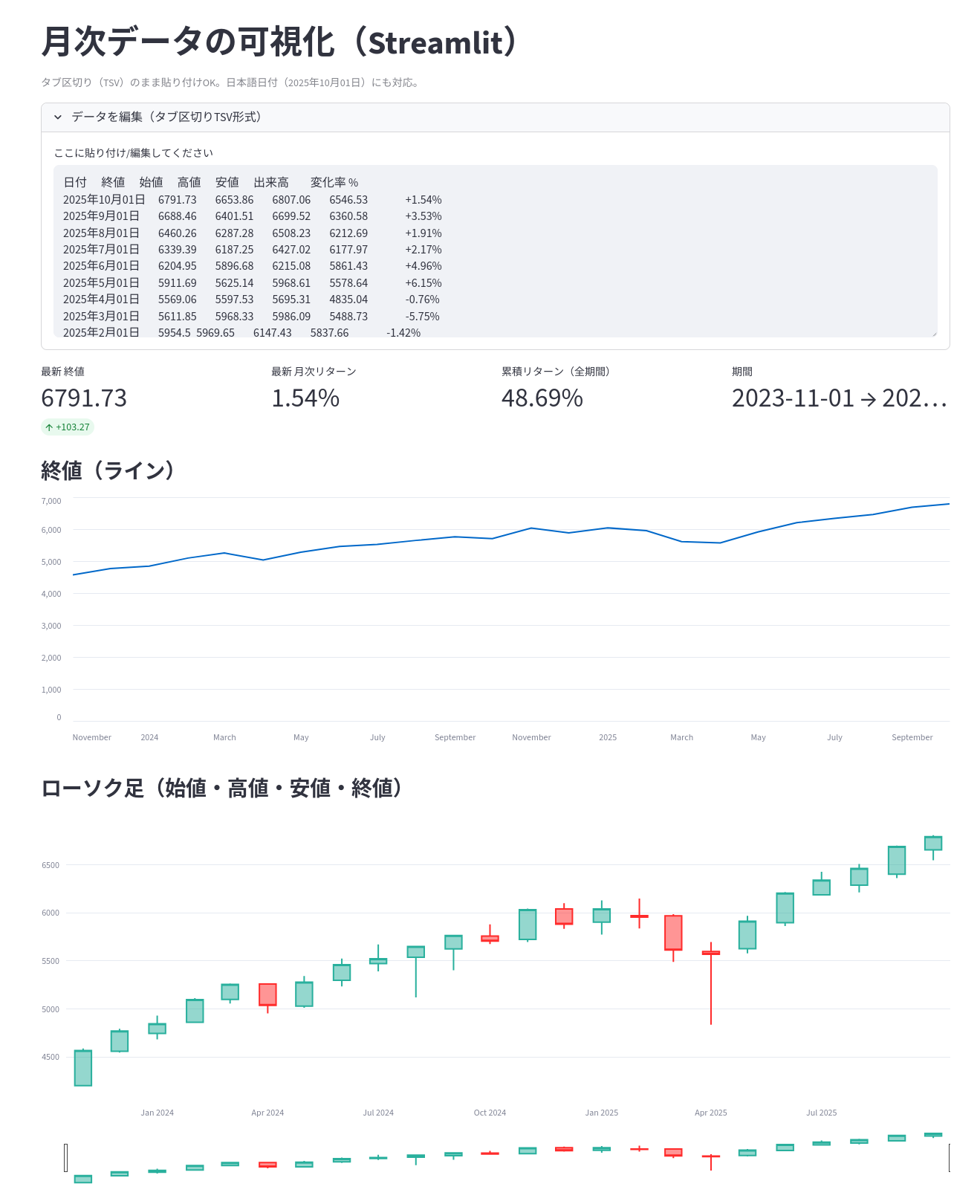
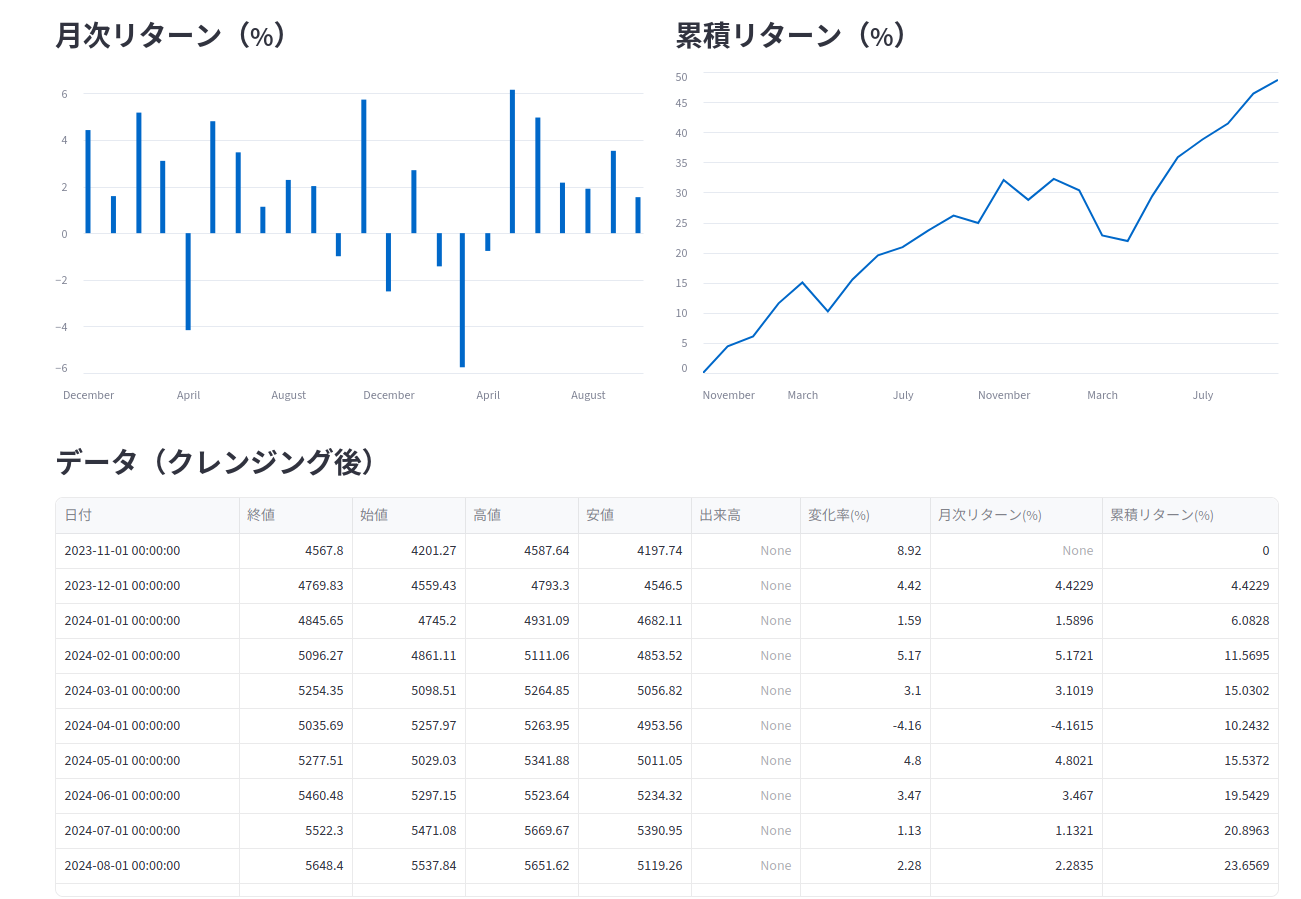
ブラウザの「データを編集」のところに、違うデータを貼り付けてみます。
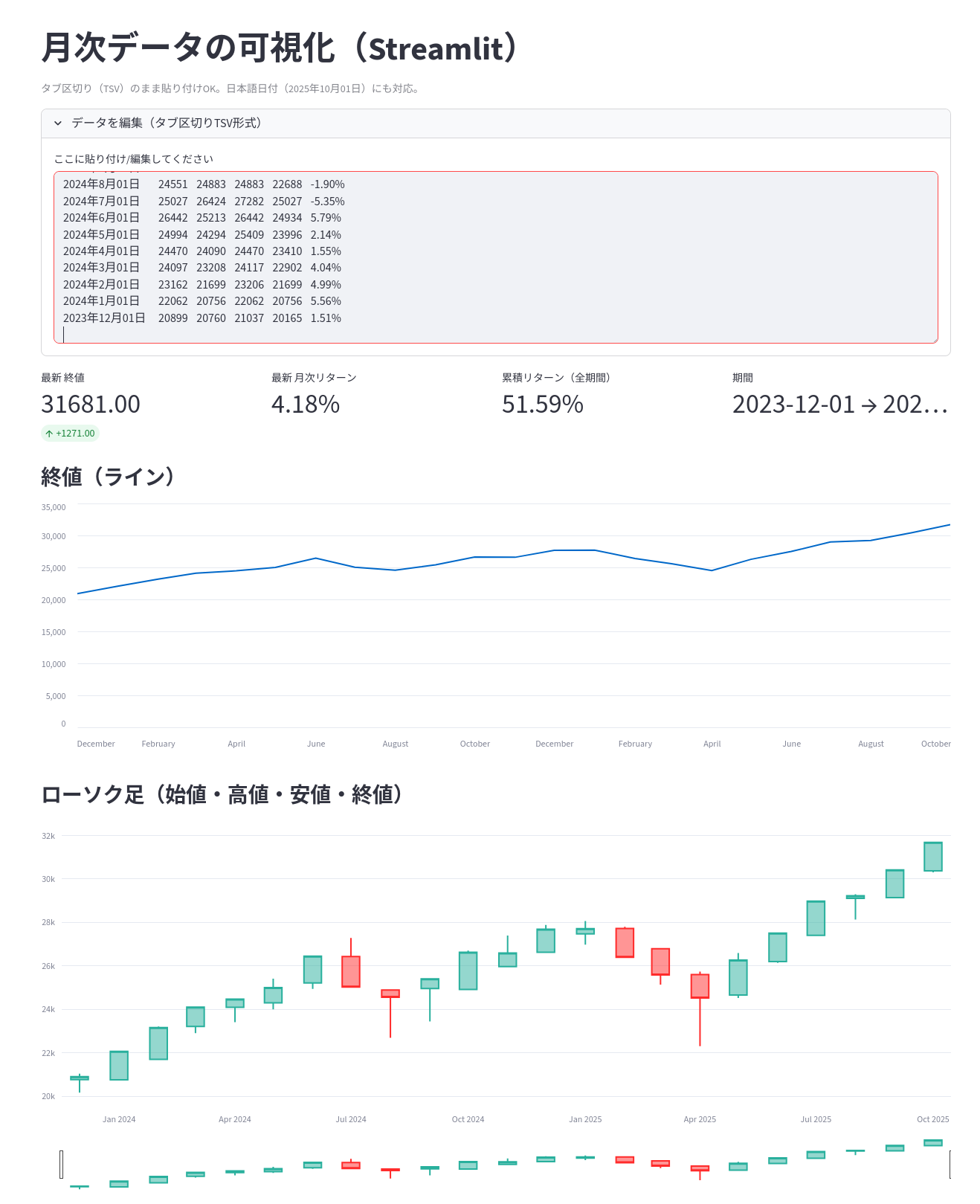
グラフが描き変わりました。
7.まとめ
Streamlitは、データを手っ取り早く可視化するには非常に良いツールです!
| 観点 | 内容 |
|---|---|
| 対象ユーザー | Pythonユーザー(特にデータ分析者・研究者・エンジニア) |
| 強み | シンプル・高速・Python完結 |
| 弱点 | 複雑UIや大規模システムには不向き |
| 主な用途 | データ可視化、ダッシュボード、MLモデルデモ |