【Polars】Parquet(パーケット)形式とは?
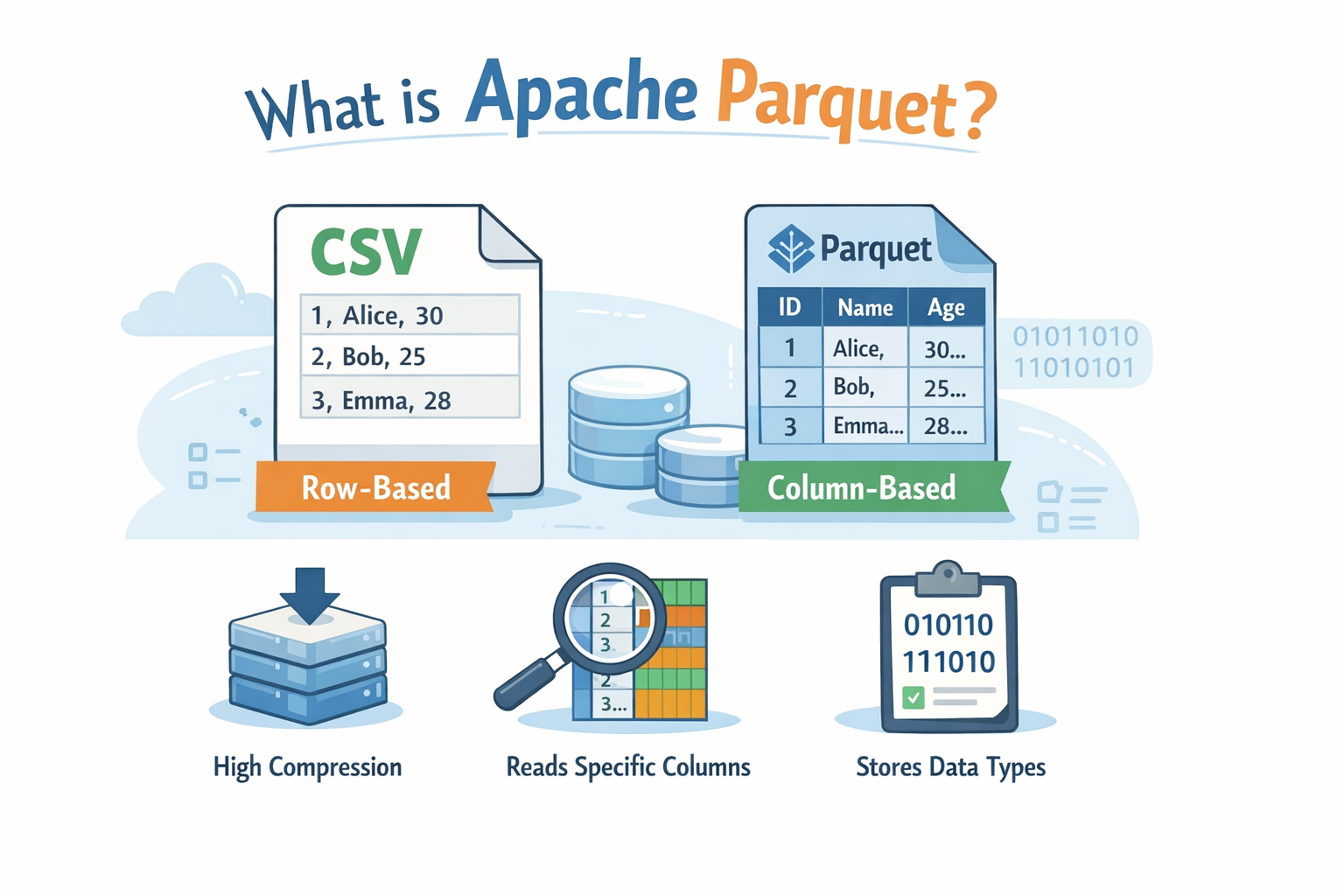
Parquet(Apache Parquet)は、
列指向(columnar)で保存されるデータファイル形式
です。
主にビッグデータ処理の世界で広く使われています。
- Apache Arrow系
- Spark
- DuckDB
- Polars
- BigQuery
- Snowflake
など、多くのデータ基盤で採用されています。
CSVとの違い
CSV(行指向)
id,name,age
1,Alice,30
2,Bob,25
CSVは「行」単位で保存されています。
- 1行ずつ並んでいる
- 人間が読める
- シンプル
- でも大規模処理には不向き
Parquet(列指向)
イメージ:
id列: 1,2,3,4,...
name列: Alice,Bob,...
age列: 30,25,...
列ごとにまとまって保存されます。
なぜ列指向が重要なのか?
例えば:
df.select("age").mean()
「age列だけ」使う処理なら、
- CSV → 全列を読み込む
- Parquet → age列だけ読む
ことが可能です。
これを:
- Projection Pushdown
- 列スキャン最適化
と呼びます。
Polarsはこの恩恵を最大限受けられます。
Parquetの主な特徴
1️ 列指向フォーマット
→ 必要な列だけ読み込める
2️ 圧縮効率が高い
- 同じ型のデータが並ぶため圧縮しやすい
- CSVよりサイズが小さくなることが多い
3️ 型情報を保持
CSVは型を持ちませんが、Parquetは持ちます。
例:
- int32
- float64
- datetime
- boolean
これにより読み込みが高速になります。
Polarsとの相性
Polarsは内部的に Apache Arrowメモリモデルを使用しています。
ParquetもArrow系フォーマットです。
そのため:
- 読み込みが非常に高速
- 余計な型推論が不要
- Lazy最適化が効きやすい
というメリットがあります。
どんな場面で使う?
| 用途 | 推奨形式 |
|---|---|
| 人間が目視 | CSV |
| 大規模データ処理 | Parquet |
| 分析基盤 | Parquet |
| 高速処理 | Parquet |
まとめ
Parquetは:
- 列指向
- 高圧縮
- 型付き
- ビッグデータ向き
という特徴を持つフォーマットです。
Polarsを本気で使うなら、
CSVよりParquetを使う
という考え方が基本になります。