【LoRA】少ないデータで、AIモデルをチューニングする

概要
今回は、画像生成モデルStable Diffusionを使って、当ブログの英語の記事で登場するEmiさんのイラストが簡単に生成できるようにしたいと思います。

そのために、LoRAという技術を使います。
LoRA(Low-Rank Adaptation)とは、AIモデルのファインチューニングを効率的に行うための技術です。特に大規模言語モデル(LLM)や画像生成AIの微調整に用いられ、少ない計算資源で高品質なカスタマイズを可能にします。
LoRAは、モデルの重みを直接変更するのではなく、低ランクの行列を挿入して学習することで、従来のファインチューニングよりも少ない計算コストで高い性能を維持できます。
🧠 LoRAの数学的な挿入位置
元の重み W を以下のように拡張します:
W' = W + α * (BA)
A:低ランクの行列(学習する) B:低ランクの行列(学習する) α:スケーリング係数(学習時や推論時に設定)この BA 部分だけが学習され、元の W は固定のままです。
📌 実行時(推論時)の仕組みLoRAで生成された .safetensors ファイルは、推論時にベースモデルに一時的に差し込まれる形で使用されます。つまり:
ベースモデルはそのままロードされる LoRAファイルを読み込むことで、対象の中間層に BA を加算 出力はカスタマイズされた結果になる
元のモデル自体をチューニングするDreamBoothと比較すると次のようになります。
🔧 1. モデル重みの更新範囲(パラメータ数)
| 項目 | DreamBooth | LoRA |
|---|---|---|
| パラメータ数 | 多い(数百MB〜数GB) | 非常に少ない(数MB) |
| 学習対象 | 元モデルの重みを直接更新 | 特定の層に追加する小型の重みだけを学習 |
| 元モデルへの影響 | 直接上書き(フルファインチューニング) | 元モデルはそのまま(差分学習) |
🧠 2. 用途や目的
| 用途 | DreamBooth | LoRA |
|---|---|---|
| 高精度に新しい概念を学習させたいとき | ◎ | △(精度より効率) |
| 軽量で多数のキャラやスタイルを切り替えたいとき | △ | ◎ |
| 商用モデルなど元モデルを改変したくないとき | △ | ◎ |
🏃♂️ 3. 学習時間・GPUメモリ
| 項目 | DreamBooth | LoRA |
|---|---|---|
| 学習時間 | 長い | 短い |
| GPUメモリ消費 | 多い(16GB以上が望ましい) | 少ない(VRAM 8GBでも可能) |
| 保存サイズ | 大きい(例:700MB~2GB) | 小さい(例:数MB〜50MB程度) |
私のPCのVRAMは8GB(新しいの欲しい…)なので、LoRAを選択しました。
今回は、LoRAのツールの中でも人気の「Kohya_ss」を使っていきます。
■使用環境
GPU: NVIDIA RTX 2070(VRAM 8GB)
OS: Ubuntu24.04
その他:Python3.10、Kohya_ss、Huggingface
■実行手順
1. kohya_ssのインストール
$ git clone https://github.com/bmaltais/kohya_ss.git
Cloning into 'kohya_ss'...
remote: Enumerating objects: 15064, done.
remote: Counting objects: 100% (653/653), done.
remote: Compressing objects: 100% (180/180), done.
remote: Total 15064 (delta 557), reused 517 (delta 473), pack-reused 14411 (from 4)
Receiving objects: 100% (15064/15064), 23.55 MiB | 19.55 MiB/s, done.
Resolving deltas: 100% (10554/10554), done.
$ cd kohya_ss/
$ ./setup.sh
自動でPythonの仮想環境を作って、インストールを開始します。
インストールが完了したら、Python仮想環境に入りaccelerate configを実行して、高速学習フレームワーク(accelerate)の初期設定を行います。
$ . venv/bin/activate
$ accelerate config
In which compute environment are you running? **This machine**
Which type of machine are you using? **No distributed training**
Do you want to run your training on CPU only (even if a GPU / Apple Silicon / Ascend NPU device is available)? [yes/NO]: ** NO**
Do you wish to optimize your script with torch dynamo?[yes/NO]: **NO**
Do you want to use DeepSpeed? **NO**
What GPU(s) (by id) should be used for training on this machine as a comma-seperated list? [all]: **Enter**
Would you like to enable numa efficiency? (Currently only supported on NVIDIA hardware). [yes/NO]: **NO**
Do you wish to use FP16 or BF16 (mixed precision)?
Please select a choice using the arrow or number keys, and selecting with enter
no
➔ **fp16**
bf16
fp8
以上で設定は完了です。
Tkinterをインストールしていない場合は、sudo apt install python3.10-tkを実行してインストールしておきます。
2. Huggingfaceにログイン
また、Huggingfaceからモデルをダウンロードするので、kohya_ssを起動する前に、Huggingfaceにログインしておきます。
$ . venv/bin/activate
(venv) $ huggingface-cli login
_| _| _| _| _|_|_| _|_|_| _|_|_| _| _| _|_|_| _|_|_|_| _|_| _|_|_| _|_|_|_|
_| _| _| _| _| _| _| _|_| _| _| _| _| _| _| _|
_|_|_|_| _| _| _| _|_| _| _|_| _| _| _| _| _| _|_| _|_|_| _|_|_|_| _| _|_|_|
_| _| _| _| _| _| _| _| _| _| _|_| _| _| _| _| _| _| _|
_| _| _|_| _|_|_| _|_|_| _|_|_| _| _| _|_|_| _| _| _| _|_|_| _|_|_|_|
A token is already saved on your machine. Run `huggingface-cli whoami` to get more information or `huggingface-cli logout` if you want to log out.
Setting a new token will erase the existing one.
To log in, `huggingface_hub` requires a token generated from https://huggingface.co/settings/tokens .
Enter your token (input will not be visible): アクセストークンを入力
Add token as git credential? (Y/n) n
Token is valid (permission: read).
The token stable-diffusion-v1-5 has been saved to /home/sue/.cache/huggingface/stored_tokens
Your token has been saved to /home/.../.cache/huggingface/token
Login successful.
Huggingfaceに登録していない方は、https://huggingface.co/ から登録しアクセストークンを発行してください。
3. トレーニング用画像の準備
トレーニング用の画像の作成方法は、下記のURLに簡単なチュートリアルがあったので、これに従って準備しました。
https://www.canva.com/design/DAFcn1l_ulE/view#1
IMGフォルダを作成し、その中に5_emi_personフォルダを作成し、そのフォルダ内に下図のような画像とテキストファイルを準備しました。
画像は、512×512ピクセルに解像度を統一しています。
IMG
└── 5_emi_person
├── 1.png
├── 1.txt
├── 2.png
├── 2.txt
├── …

テキストファイルには、同じファイル名の画像の詳細な説明プロンプトを記述しておきます。
たとえば、1.txtであれば下記のようなプロンプトを作成しました。
Emi, cute girl, sleeping, smiling, happy, closed eyes, lying in bed, under blanket, long hair, brown hair, wavy hair, cardigan, peaceful, relaxed, anime style, soft lighting, warm atmosphere, sepia tone
4. kohya_ssの起動
kohya_ssを起動するには、gui.shを実行します。
* Running on local URL: http://127.0.0.1:7860
* To create a public link, set `share=True` in `launch()`.
のように表示されますので、http://127... のURLにアクセスします。
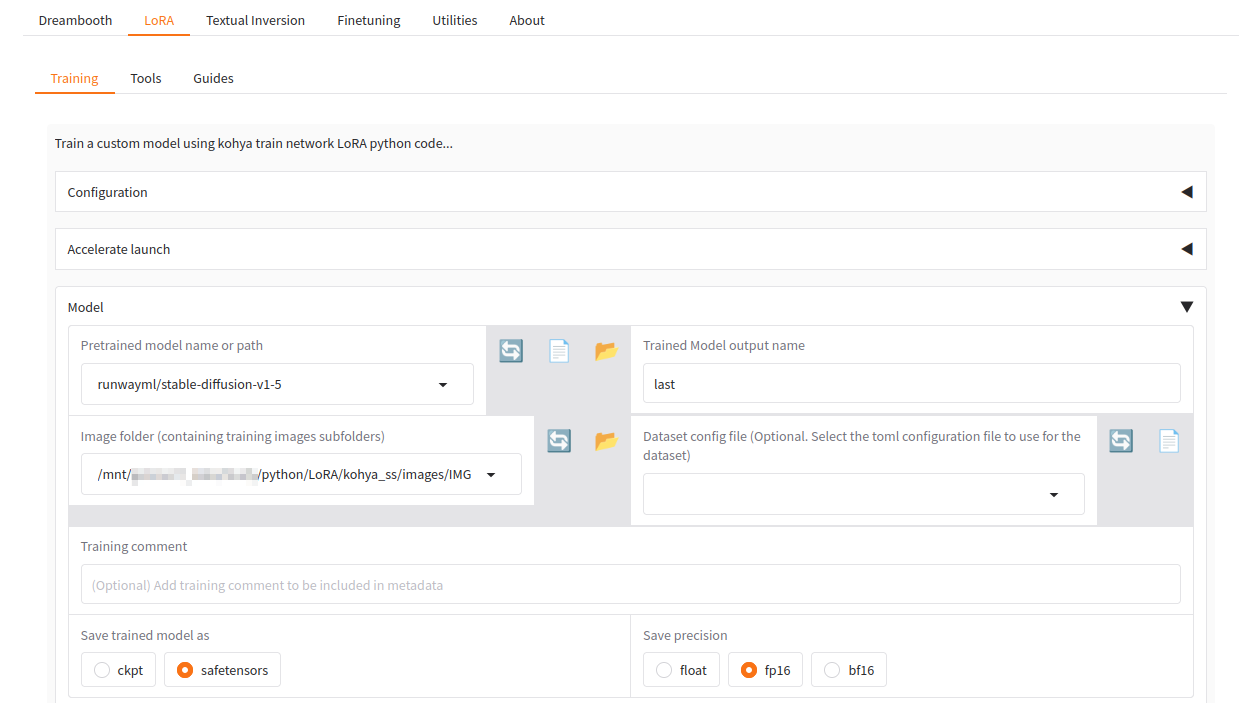
LoRAタブを選択し、必要な項目を設定
| 設定項目 | 値(例) | 解説 |
|---|
| Pretrained model | runwayml/stable-diffusion-v1-5 | ベースとなるモデル(例:v1-5) |
| Image folder | path/to/your/images | 学習画像が入ったフォルダ |
| Trained Model output name | emi_lora | 出力ファイル名のベース。自由でOK |
| Output directory | path/to/your/output | 訓練したモデルの保管フォルダ |
| Max resolution | 512,512 | 一般的な画像はこれでOK。アニメ系なら 768 も可 |
| Train Batch size | 2 | RTX 2070なら 2 で動作可能。メモリ不足時は 1 に |
| Max train epoch | 10 〜 20 | 少量画像なら 10〜20 epoch 程度でOK |
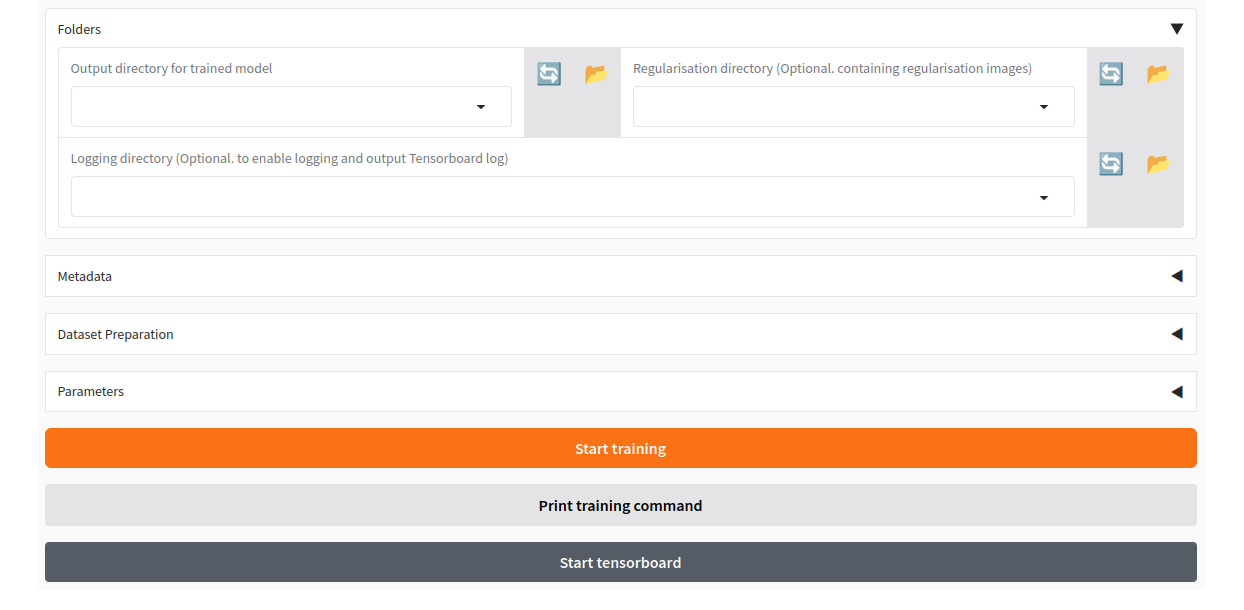
設定が終わったら、Start trainingボタンを押します。
私のPCだと、3分弱で学習が完了しました。
5. トレーニングしたLoRAを試す
学習が終わったら、Output directoryに指定したフォルダに、Trained Model output nameに指定したファイル名.safetensorsファイル(例:emi-stable-diffusion.safetensors)ができています。
これを使って、画像を生成してみましょう。
画像の生成には、kohya_ssとは別の生成ソフトが必要です。
今回は、AUTOMATIC1111をインストールして、画像を生成しました。
$ git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git
$ cd stable-diffusion-webui
$ mkdir -p models/Stable-diffusion
$ cd models/Stable-diffusion
$ wget https://huggingface.co/runwayml/stable-diffusion-v1-5/resolve/main/v1-5-pruned.safetensors
また、先ほど学習させたモデルをLoraフォルダにコピーします。
$ cp path/to/your/output/emi-stable-diffusion.safetensors path/to/LoRA/stable-diffusion-webui/models/Lora
AUTOMATIC1111も、venv環境に入ってからwebui.shを実行します。
stable-diffusion-webui$ . venv/bin/activate
(venv) $ ./webui.sh
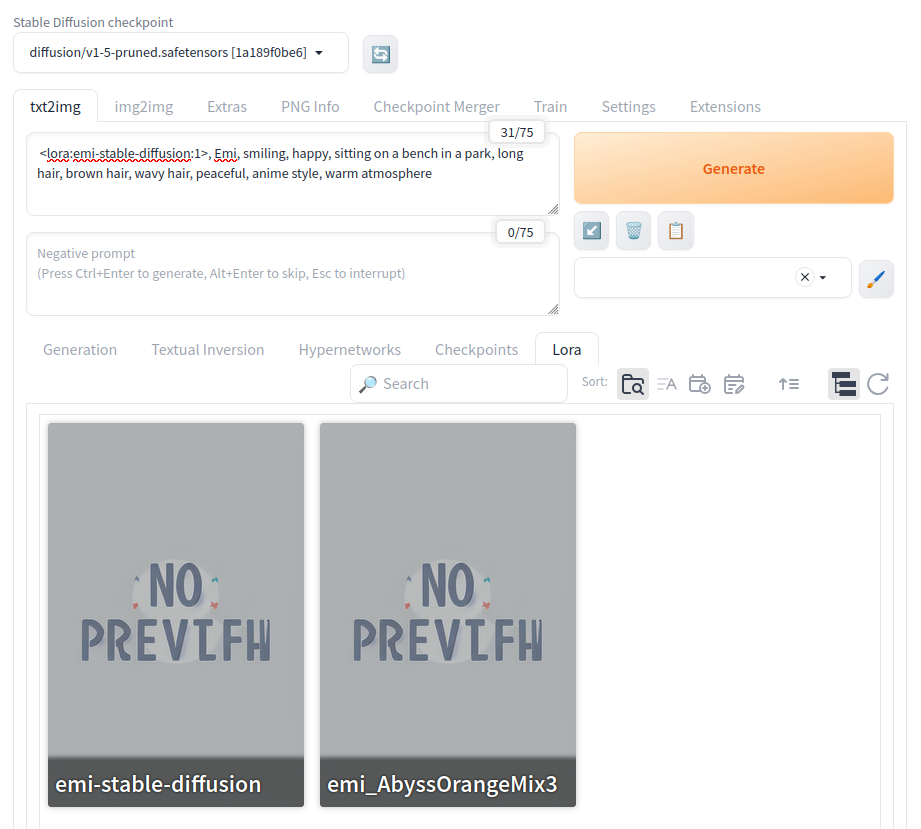
ブラウザが起動するので、モデルを選択します。
次にLoraタブを選択し、先ほど訓練させたLoRAモデルを選択します。
LoRAモデルを選択すると、プロンプト欄に<lora-emi-stalbe-diffusion:1> のように入力されます。最後の数字は、LoRAを元のモデルにどのくらい強く反映させるかを指定する倍率です。
| 用途 | 推奨強度 |
|---|---|
| 基本的な使用 | 0.7〜0.9 |
| デフォルメ強め・明確なLoRA表現 | 1.0〜1.2 |
| 複数のLoRAを組み合わせる | 0.5〜0.7 ずつがバランス良好 |
作成したいイラストのプロンプトを入力して、Generateボタンを押します。

やばい画像が生成されました -o-;;
ちなみに同じプロンプトでLoRAを適用しなかった場合は、こんな感じになりました。

こうしてみると、LoRAがかなり反映されていることがわかります。
しかし! これは、元のモデルを変えたほうがよさそう・・・
ということで、AbyssOrangeMix3でもやってみました。



やはり、元のモデル選びは大事ですね ^^;