DockerでOpen WebUI+Ollama環境を簡単構築!
LLMを手軽に使う方法とGPUトラブル対処法
1. はじめに
ローカル環境で大規模言語モデル(LLM)を試したいけれど、難しそう…と思っていませんか?
今回は、Docker を使って、話題の Open WebUI と Ollama を簡単に構築し、手軽にLLMを使える環境を作る方法をご紹介します。
さらに、私が実際にハマった「GPUが認識されない問題」とその対処法も【補足】としてまとめました!
2. Open WebUI+Ollamaとは?
- Ollama:ローカルでLLMを動かせるエンジン。各種モデル(例:Gemma、Llama3など)を簡単に利用可能。
- Open WebUI:Ollamaをブラウザから操作できる便利なフロントエンド。
この2つを組み合わせることで、まるでChatGPTのようにローカル環境でLLMが扱えるようになります!
3. Dockerを使った構築手順
① 必要環境
- Docker & Docker Compose v2 がインストール済みであること
② docker-compose.yml の作成
まず、プロジェクト用のディレクトリ(フォルダ)を作成します。ここにDocker関連のファイルをまとめて管理します。
mkdir my-ollama-setup
cd my-ollama-setup次に、このディレクトリ内に docker-compose.yml という名前のファイルを作成し、以下の内容をコピー&ペーストしてください。
Linux環境の場合は以下のコマンドでファイルを作成できます。
nano docker-compose.ymlエディタが開いたら、下記の内容を貼り付けて保存します。(保存方法:Ctrl + O、終了:Ctrl + X)
以下がその内容です。
services:
ollama:
restart: always
container_name: ollama
image: ollama/ollama
ports:
- "11434:11434"
runtime: nvidia
environment:
- OLLAMA_KEEP_ALIVE=-1
volumes:
- ./volume/ollama:/root/.ollama
open-webui:
image: ghcr.io/open-webui/open-webui:main
container_name: open-webui
ports:
- "3001:8080"
extra_hosts:
- "host.docker.internal:host-gateway"
environment:
- WEBUI_AUTH=True
volumes:
- ./volume/open-webui:/app/backend/data
tika:
image: apache/tika:latest
container_name: tika-server
ports:
- "9998:9998"docker-compose.yml
③ コンテナ起動
docker compose up -d
これで、Open WebUI がポート 3001 で起動します!
4. Open WebUIからOllamaを操作する方法
(1) ブラウザで http://localhost:3001 にアクセス。

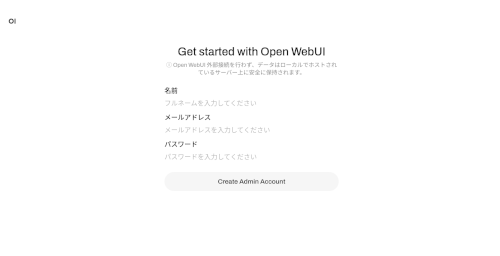
(2) 初回はアカウント登録。
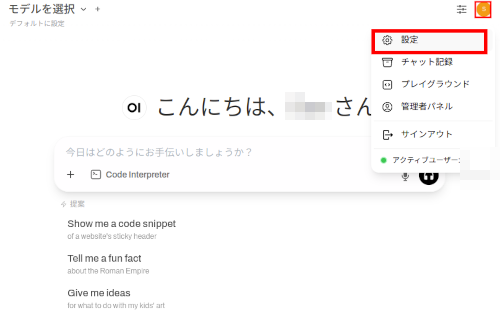
(3) 右上のメニューボタンから、「設定」を選択。
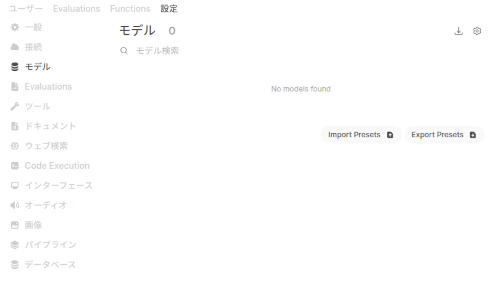
(4) メニューから「管理者設定」−「モデル」の順に選択。
(5) 「Manage Models」ボタンから、『gemma3:4b』(自分の環境に合わせてください)と入力し、モデルをプル。Ollamaが自動でモデルをダウンロードし、すぐにLLM体験ができます。
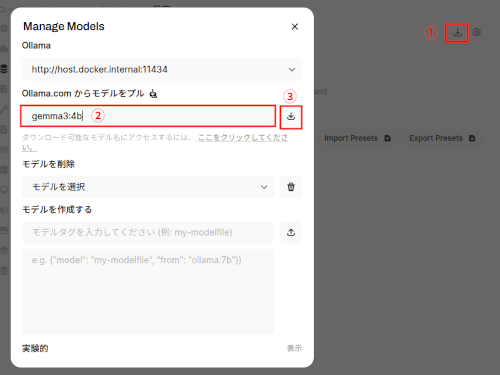
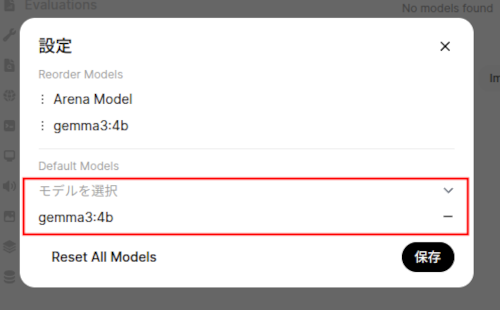
(6) モデルがプルされたら、「モデルを選択」でプルしたモデルを選択し、「保存」ボタンをクリック
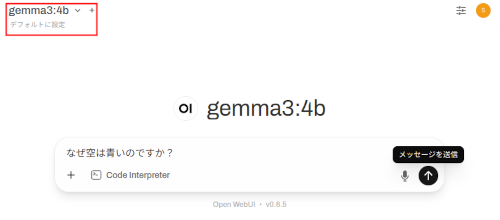
(7) ダウンロードしたモデルを選択し、プロンプトを入れて動作を確認。
5. 【補足】GPUが認識しない時の対処法
私の環境(Ubuntu 24.04 + RTX 2070)では、dockerのからGPUが認識されず苦戦しました。 同じ問題に直面した方は、以下をチェックしてください!
✅ 主なチェックポイント
/etc/nvidia-container-runtime/config.tomlのno-cgroupsが true になっていたので false にする。- ドライバは安定版 535系 を使用する。
nvidia-container-toolkitを導入し、Dockerを再起動。
6. まとめ
- Dockerを使えば、誰でも簡単にローカルLLM環境を構築可能!
- Open WebUIで快適な操作性を実現。
- GPUを活用すれば、さらに高速な推論が可能に!
トラブルがあっても、原因を理解すれば必ず解決できます。
ぜひ、あなたの環境でも試してみてください!