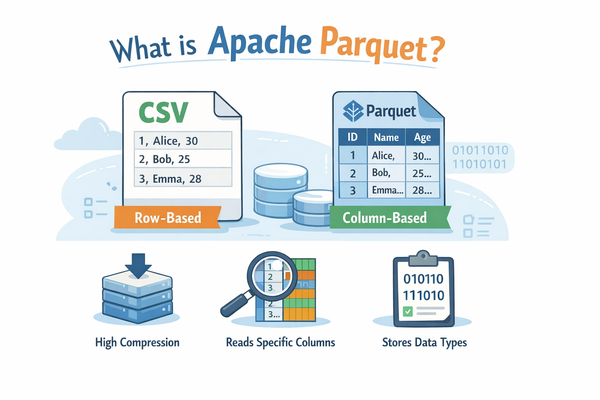
Parquet(Apache Parquet)は、
列指向(columnar)で保存されるデータファイル形式
です。
主にビッグデータ処理の世界で広く使われています。
* Apache Arrow系
* Spark
* DuckDB
* Polars
* BigQuery
* Snowflake
など、多くのデータ基盤で採用されています。
CSVとの違い
CSV(行指向)
id,name,age
1,Alice,30
2,Bob,25
CSVは「行」単位で保存されています。
* 1行ずつ並んでいる
* 人間が読める
* シンプル
* でも大規模処理には不向き
Parquet(列指向)
イメージ:
id列: 1,2,3,4,...
name列: Alice,Bob,...
age列: 30,